As mentioned in the first part of this progress report, Godot is taking part in the Google Summer of Code (GSoC) programme for the second time, and we have 8 students working on specific projects for Godot Engine.
We’re now in the middle of the GSoC 3-months coding period, and we asked students to write a progress report to present their project and the work done so far. The 8 reports are split over two posts, the first 4 of which was posted yesterday. This second post will cover the remaining 4 projects.
Here is the list of projects and students with links to the relevant sections.
Part 1 (previous post):
Part 2 (this post):
Rewriting Godot’s Light Mapper – Joan Fons Sanchez
- Project: Rewriting Godot’s Light Mapper
- Student: Joan Fons Sanchez (JFonS)
- Mentors: Juan Linietsky (reduz) and Bastiaan Olij (BastiaanOlij)
- Repository: https://github.com/JFonS/godot/tree/lightmapper
Project description
Light maps are a really easy way to improve performance on statically lit scenes. Instead of computing the amount of light that reaches a certain surface every frame for every light source, we precompute all this information and store it in a single texture. This means having lots of lights no longer creates a performance hit on the rendering pipeline, since all we need to do is sample a single texture and we get the amount of light coming from all light sources.
Godot’s 3.1 light mapper is based on the same approach used in global illumination. That means the whole scene is subdivided in a regular grid of voxels and, for each of these voxels, we compute the amount of light reaching it. This allows us to have some great results for computing real time illumination, but the discretization of the scene has various downsides (e.g. some walls may be thinner than the size of a voxel, therefore they can leak light through them).
The main goal of my GSoC project is to completely rewrite the light mapper in Godot and, instead of a voxel approach, use ray tracing to compute the scene lighting. This will hopefully give better looking light maps and will reduce the amount of artifacts such as self occlusions or light leaks.
Current progress
During the first weeks of coding I added caching to UV2 generation. The process of generating light map texture coordinates takes a while, and it was being triggered on every scene reimport. By adding a simple cache to it, we made it so that light map texture coordinates are only computed when there’s an actual change to the geometry of the mesh.
With that simple task out of the way my main focus went to getting the direct illumination pass done. That involved generating the actual light map texture and, for every light inside the BakedLightmap node, compute the amount of light reaching every texel.
Here you can see the Sponza demo model, with baked direct lighting, and the corresponding light map:


Note that this first pass is not taking occlusion into account yet. That will be added in the following weeks.
Next steps
I’m currently working on integrating Embree as a ray tracing library into the Godot editor. Once I get it fully working I will use it to add occlusion tests to the direct light pass as well as doing all the required computations for indirect lighting.
The first results will probably look noisy and with graphical artifcats, so I will spend some time implementing all the tips and tricks detailed in this wonderful article. If I still have some time left I will take a look at adding some sort of AI denoiser, but I can’t promise anything :)
Static Analyzer for GDScript – Suhas Prasanna
- Project: Static Analyzer for GDScript
- Student: Suhas Prasanna (psuhas77)
- Mentors: George Marques (vnen) and Bojidar Marinov (bojidar-bg)
- Repository: https://github.com/psuhas77/godot/tree/gsoc
Introduction
While making medium to large scale games in Godot, many small bugs start to creep in that cannot be caught by the compiler. These can only be dealt with manually while debugging. This project will build a tool to be used semi-regularly to highlight these problematic pieces of code in an automated fashion. This essentially extends the scope of static checks, currently just done within each script, to operate across scripts and scenes.
It can be used to deal with things such as non-existent node being referenced in a get_node() call, wrong arguments in a function connected to a signal, etc.
What kind of static checks can be expected?
Within the time frame of this GSoC, these are the static checks that can be expected to be completed:
- Check to ensure a script does not refer to a non-existent node in the scene (this can be a problem when nodes are deleted or the tree is re-organized).
- Check to ensure that a script does not refer to a non-existent method/property in the node (this can be a problem when there is a change type operation).
- Check to ensure that the arity and type of arguments declared in a function connected to a signal are correct.
However, this is not an exhaustive list and hopefully many more can be completed by the time GSoC ends.
Current state
UI
The UI so far is still a work in progress (since most of the work done so far is behind the scenes), however you can expect the final tool to reside here:
Behind the scenes
The way I’m going about this is to essentially go through each scene and within that, traverse through each script to check if there is any potentially problematic code. Then that particular code can be checked to ensure that it is correct (e.g. ensure that the NodePath in a get_node call does point to an actual node). Further optimizations will be done so it isn’t necessary to process the same scripts again and again.
Currently, the mechanism to traverse from scene to scene, as well as ensure that the scene files are valid, is complete. Most of the mechanism to traverse through any particular script is done as well. So, it can run through each scene file, make sure it’s valid, and extract scripts from the nodes within the scenes to perform static checks on them.
What next
The Scene Traversal mechanism needs to be fully finished. Once that is done, I can start working on the static checks. The few mentioned in this post will be created first and based on the time remaining, more can be implemented. The last step will be to tidy up the UI and ensure that the tool works with extensive testing. Looking forward to a fruitful next couple of months.
Motion Matching Implementation Using KD Trees – Aditya Abhiram
- Project: Motion Matching Implementation Using KD Trees
- Student: Aditya Abhiram (Aa20475)
- Mentors: Juan Linietsky (reduz) and karroffel
- Repository: https://github.com/Aa20475/godot/tree/godot-motion-matching
Introduction
Hey! This is Aditya Abhiram a.k.a. DestinyGamer. I am working on the implementation of Motion Matching in Godot.
First of all, I want to thank the Godot project and my mentors, Juan Linietsky and karroffel, for giving me a chance to work on this project.
Godot, being an open source game engine, was built with a never-ending wish of adding new features to it.
Motion matching is one of the latest features in game animation which is quite revolutionary. Usually, setting up a basic animation system needs a lot of work and time. Even after that, we barely manage to make a perfect one. Motion matching, on the other hand is a method where the computer chooses the best pose for each frame by itself from a huge database of motion capture (MoCap) data using some algorithm.
Choose the best pose for each frame and jump to it!
This wonderful feature needs to be included in Godot!
Overview
This project has three parts:
- Cost function
- Future trajectory prediction model
- KDTrees for KNN search (optimisation)
We started off by collecting datasets for testing while reduz worked on the UI of the editor. Along with data collection, I tried out implementing KDTree and KNN search. The UI was ready by mid June and then I started adding and testing the KDTree and KNN search algorithms with it.
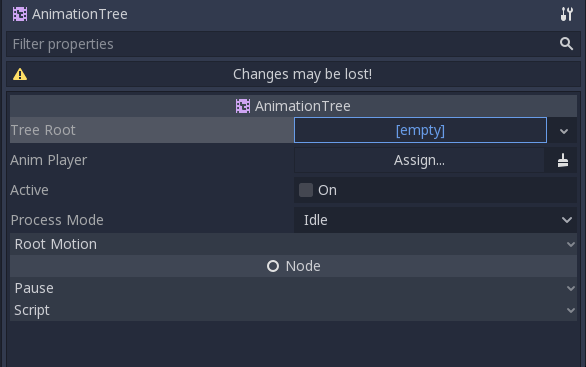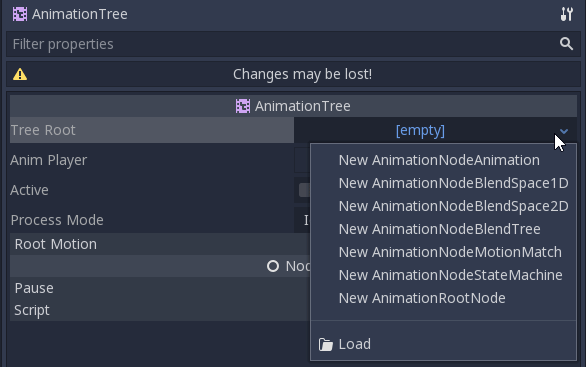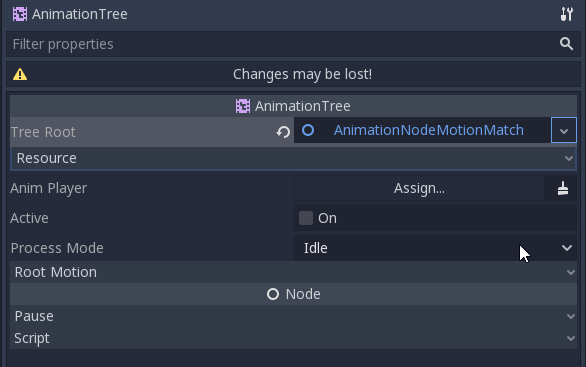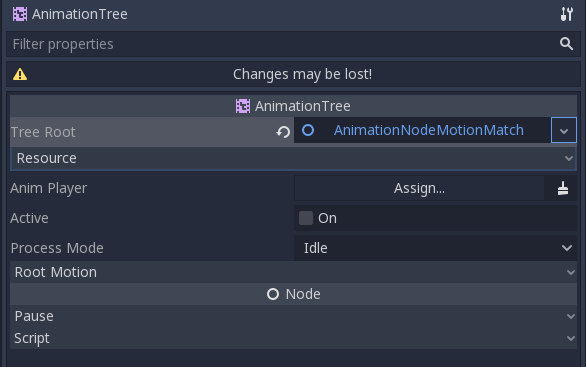
AnimationNodeMotionMatch in AnimationTree:
AnimationNodeMotionMatchEditor UI:
Just before the first evaluation [ed. after one month of coding], I successfully added KDTree and KNN search to the AnimationNodeMotionMatch.
During the evaluation period, I tried making a simple future trajectory prediction models.
After that, I started implementing Pose and Trajectory Matching (i.e. calculating the cost function using pose and root trajectory comparisons) without including KDTrees yet (just as a brute force attempt). I’m still working on fixing the crashes in this matching.
‘Animation Player not set’ error:
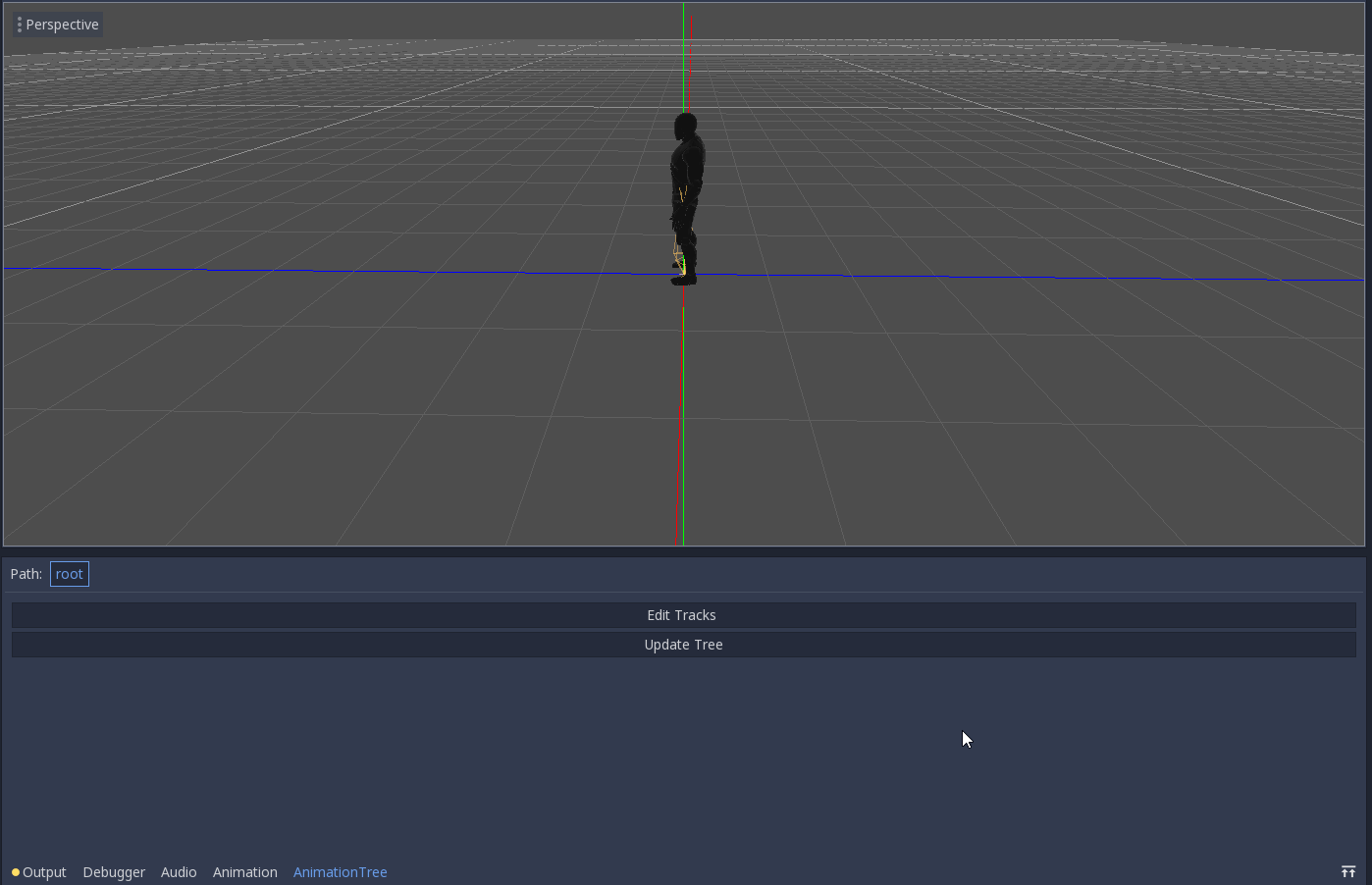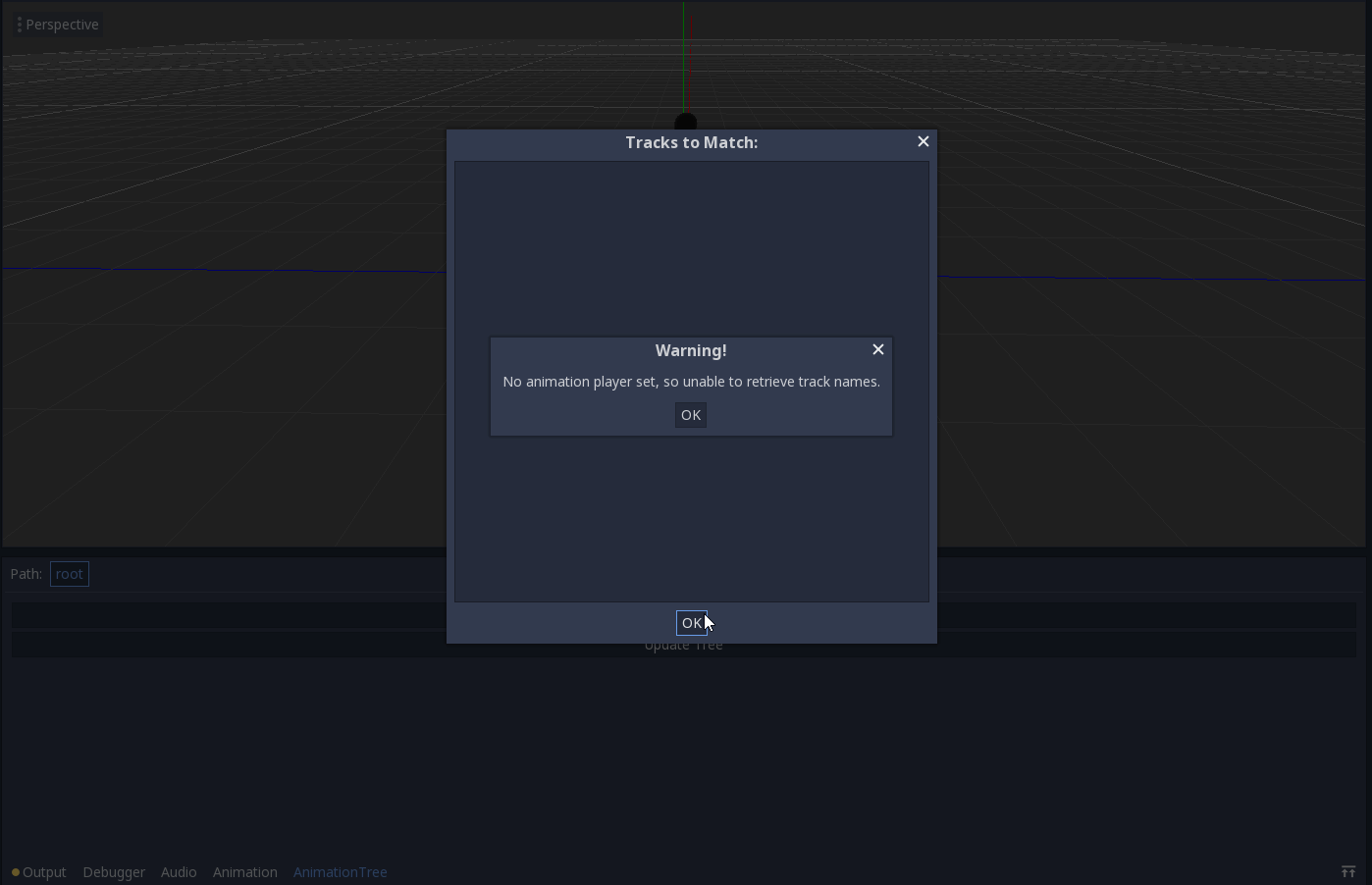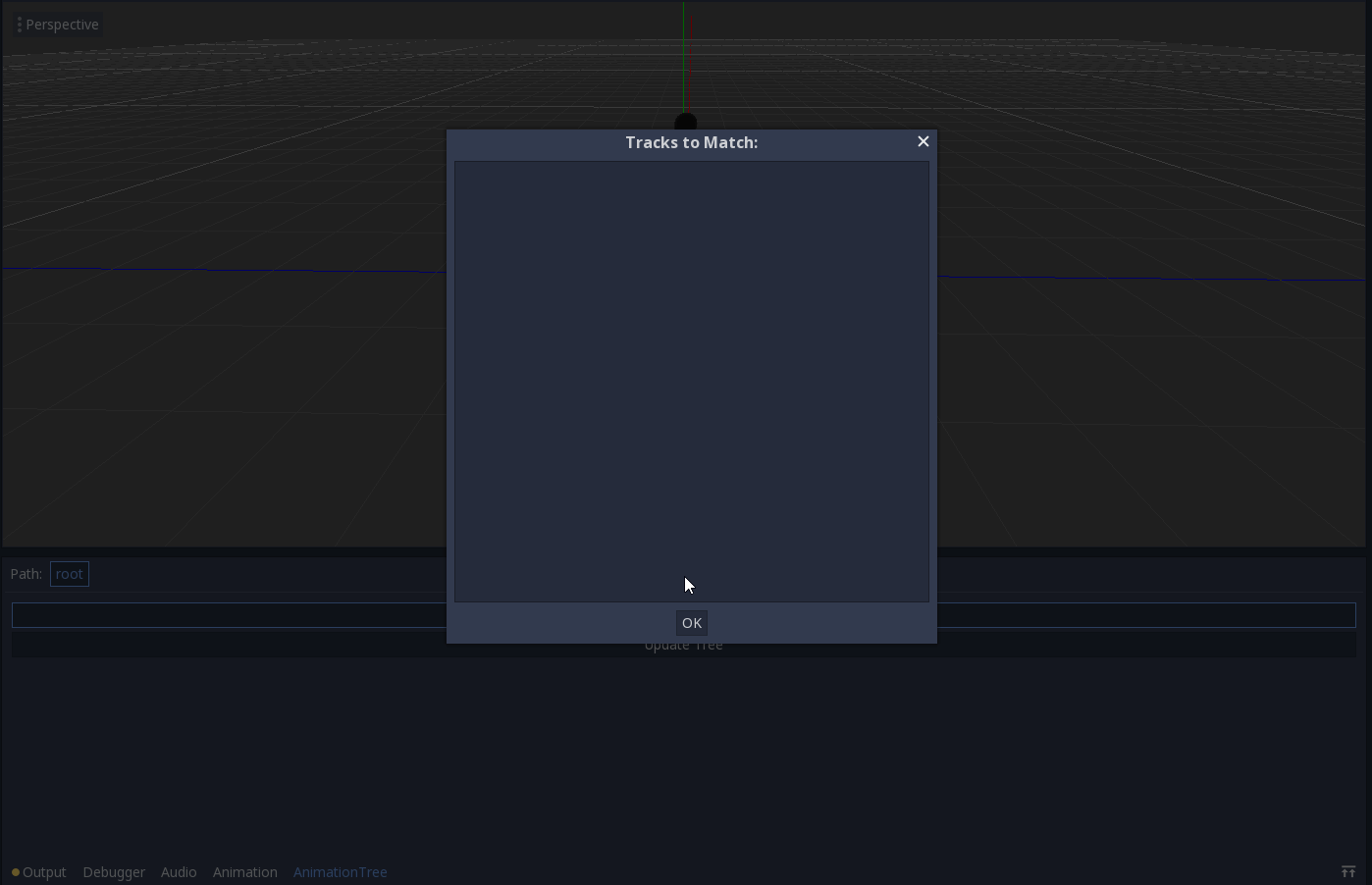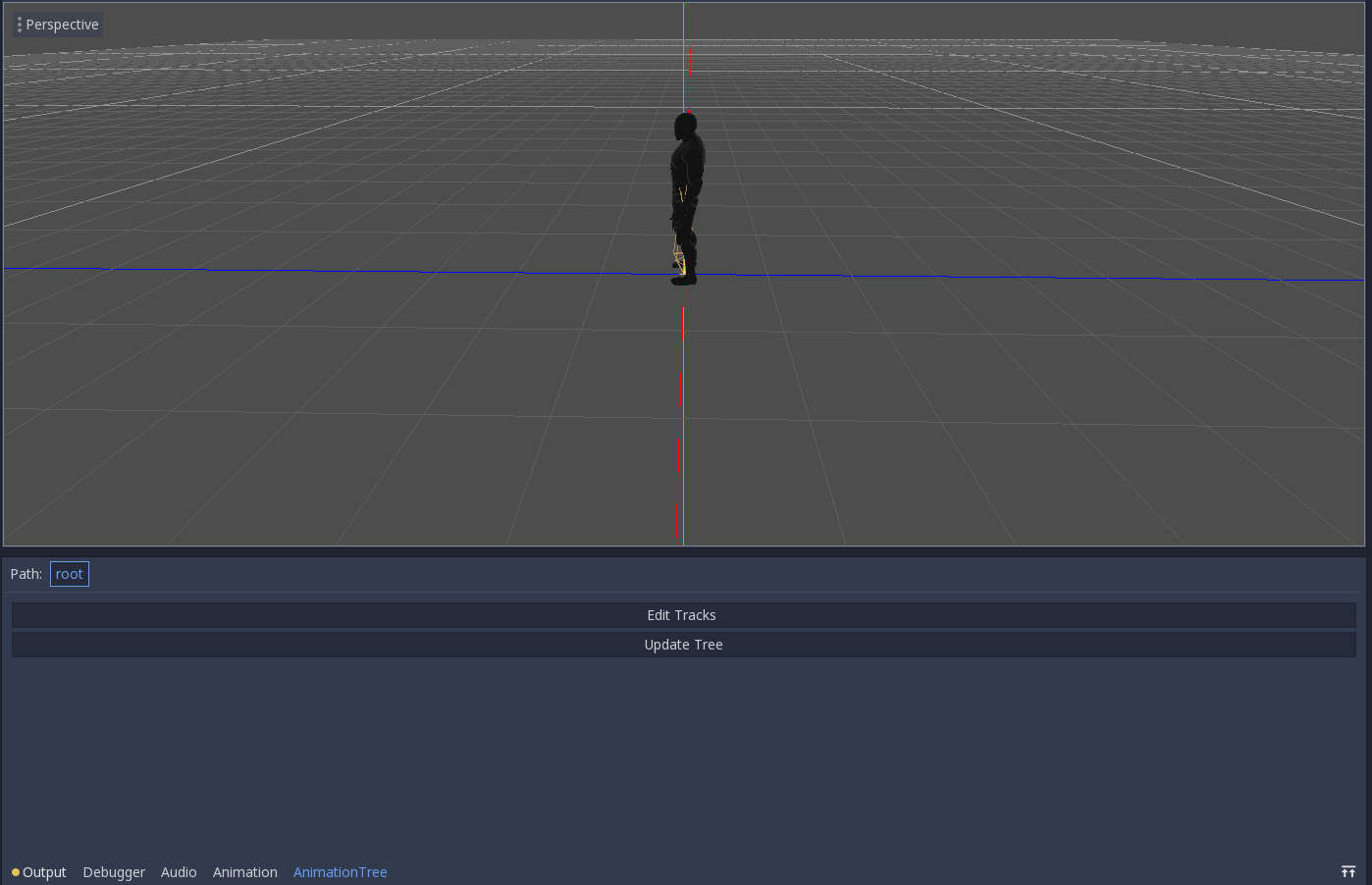
‘Root Motion Track not set’ error:
Things to do
- Getting Pose and Trajectory Matching running without any crashes.
- Adding Velocity Matching too so that the matching gets more natural.
- Taking past data into account during matching, so that we won’t ignore weight-shifts and get a natural looking animation.
- Replacing the brute force approach with KNN search using KDTrees.
- Adding sliders for parameters such as Pose and Trajectory, etc.
- Many more additions needed to the UI.
Asynchronous Cached File Access – Raghav Shankar
- Project: Asynchronous Cached File Access
- Student: Raghav Shankar (WarpspeedSCP)
- Mentors: Ariel Manzur (punto-) and HP van Braam (hpvb)
- Repository: https://github.com/WarpspeedSCP/godot/tree/wip-patch
About this project
Godot Engine is pretty easy to use for most things and is becoming a better competitor to Unreal Engine and Unity by the day. But one area where it’s lagging behind is in the way it handles file and network IO on various platforms, especially on systems like consoles.
Nowadays, all IO operations are cached to speed up access to data from hard drives or the network. The cache sits in RAM and holds on to information that is frequently accessed so we don’t need to wait a long time for the data. For desktop and mobile systems (like android and iOS), this may be less of a problem because the OS can provide caching for disk and network IO. But consoles and other more specialised systems may not have an OS that does this for us, which means we may need to do the caching ourselves.
The current mechanism that Godot Engine provides for such cases is pretty bad – it only reads ahead, it doesn’t allow for seeking backwards and it’s only for files on disk. My project aims to provide a more flexible solution that manages caching centrally, and allows for using different caching strategies as the situation demands through a C++ module which can be dropped in at compile time.
Current progress
As of now, about half of the project’s goals are complete. I have created a cache structure that can hold data from multiple files which may be cached under different policies like FIFO (first in, first out) or LRU (least recently used).
The system is designed so that the actual interaction with the network/file system, which may take time, takes place on a separate thread alongside the rest of the engine. If data is already in the cache because we’ve read ahead a little, access will be much faster. Otherwise, we only need to wait a little while the bits of the file that are needed are loaded in the background.
The engine sees a normal file interface which it can use to read, write and seek within a file. Behind this frontend, the module keeps track of what parts of the file are in the cache, and loads more of the file into the cache on demand.
The cache breaks each file into a bunch of equally sized parts which can be easily shifted in and out of the cache.
There are three different caching algorithms I’ve set up.
FIFO (First In First Out)
FIFO is a straigntforward algorithm that just reads ahead by some number of parts. If the cache runs out of space, this algorithm discards the oldest part first. This may be ok for a file that doesn’t ever need to be seeked through, and which will only be read sequentially.
LRU (Least Recently Used)
LRU is a great caching algorithm that handles cases where we may read old data again very well. My particular implementation keeps a list of parts in order of the time they were accessed. When we run out of space, we discard the part that was accessed least recently (hence the name).
Permanent store
Sometimes we may want to use a file for a really long time, to the point where it’s probably going to be open the entire time the game is running. Maybe it’s for logging, or for autosaving progress. I’ve included a caching policy for this use case as well. Parts of files that are accessed with this policy are cached in the same manner as with LRU, except that permanent cached parts cannot be replaced by parts of other files.
For example, if we have a choice betweeen a permanent part and an LRU part which may be replaced, we must choose to replace the LRU part instead of the permanent one.
Summary
Currently, files can be read from and I’ve got some GDScript integration set up to test things. I want to be able to write to files as well, but right now there are still a few bugs in the read logic that I need to squash.
What’s next?
For now, the module uses standard library file handling functions in the backend. These can be switched out for the platform specific unbuffered IO functions. That way, things won’t be cached twice by both the OS and the engine. I plan to add unbuffered versions of the FileAccess class specific to each platform for this reason.
By August, this module should be feature complete with regards to my proposal.
What more can be done?
I want to provide support for something like magic streams, which are a way to store assets as a contiguous stream of data, where assets are stored in the order they are accessed in a game. So for a game, if the splash screen asset is loaded first, and then a character model, the magic stream for the game would have the contents of the splash image file appearing first, then the contents of the model, and so on.
Magic streams are great because they reduce the amount of time spent seeking for hard drives (since all the assets are stored contiguously in one file), and could also be useful for streaming assets over the network (just one request for all the data).
I also think this module could serve as a basis for streamlining the asset loading pipeline for Godot engine, which is currently single threaded.
That’s it for this second batch of progress reports from our GSoC students. The first four reports will be can be read in the previous blog post, and we should have a second progress report from all students towards the end of the coding period.
We hope that you will find good use cases for all the features that are being worked on, and we thank all students and mentors for their dedicated work on these projects!